绪论
因为我懒,所以熬夜。
概率 - Probability
大数定律 - Law of large number (概率的基石)
If we observe more and more repetitions of any chance process, the proportion of times that a specific outcome occurs approaches a single value.
概率 - Probability
样本空间 - Sample Space
所有可能的结果组成的集合。Set of all possible outcomes.
概率模型 - Probability Models
样本空间 $S$ 以及每个结果说对应的概率。
Probability Rule
- Legitimate values:
- Probability for sample space:
- Complement Rule
条件概率 - Conditional Probability
Definition: $P(B|A)$ represent the probability that event B happens given that event A happened.
Computation:
独立事件 - Independence
两个事件相互独立的定义:如果一个事件的发生不会改变另一个事件发生的概率,那么这两个事件相互独立。
如果两个是事件是独立的,如下关系成立:
Mutually Exclusive
如果一个事件发生了,导致另一个事件必定不可能发生,那么这样的两个事件就是Mutually Exclusive.
If one has happened, the other must not happen at all.
Mutually Exclusive & Independence
如果两个事件是Mutually Exclusive,那么他们必定不可能是Independent的。反之亦然。
An important conclusion
P.S. When $A$ and $B$ are sets,
Two-way Tables
Study two categorical variables.
组合 - Combination
Definition: $n$ 个里面选 $m$ 个
计算器:menu -> 概率 -> 组合,e.g. nCr(5, 3) = 10.
重复独立概率 - Repeated Independent Probability
例子:一个人投篮命中率 $70\%$ ,连续投 $5$ 次,恰好命中 $3$ 次的概率:
干一件事,成功率是 $p$ ,连续干了 $n$ 次,恰好成功 $m$ 次的概率:
随机变量 - Random Variable
Definition: A numerical varaible that describes the outcomes of a chance process is called a random variable.
概率分布 - Probability Distribution
Definition: The probability model for a random varaible is its probability distribution.
离散型随机变量 - Discete Random Variable
Definition: A discrete random variable $X$ takes a fixed set of possible values. The probability distribution of discrete random variable $X$ lists the values $x_i$ and their probabilities $p_i$.
离散型随机变量的期望 - Mean of Discrete Random Variable
Definition: The mean of any discrete random variable is an average of the possible outcomes, with each weighted by its probability.
P.S. 又称Expected Value,即”期望”。
离散型随机变量的方差 - Variance of Discrete Random Varaible
离散型随机变量的标准差 - Standard Deviation of Discrete Random Variable
一个重要的公式
P.S. 关于$E[X^2]$,根据定义:
随机变量的线性变换 - Linear Transformation of Random Variables
随机变量的结合 - Combining Ramdom Variables
但两个随机变量 $X$, $Y$ 互相独立时:
Binomial Settings
Definition: A binomial setting arises when we perform several independent trials of the same chance process and record the number of times that a particular outcome occurs. The four conditions for a binomial settings are:
- Binary: The possible outcomes of each trial can be classified as “success” or “failure”
- Independent: Trials must be independent, that is, knowing the result of one trail must not have any effect on the result of any other trial.
- Number: The number of trials $n$ of the chance process must be fixed in advance.
- Success: On each trial, the possibility $p$ must be the same.
要求:
- 结果只有两种,成功或失败
- 每次的事件是独立的
- 固定的次数
- 每次成功概率一样
Binomial Random Variable
Definition: The count $X$ of success in a binomial setting is a binomial random variable
二项分布 - Binomial Distribution
Definition: The probability distribution of $X$ (a binomial random variable) is a binomial distribution with parameters $n$ and $p$.
Binomial Probability
如果一个随机变量 $X$ 是而二项分布随机变量,那么 $P(X=k)$指的就是”exactly $k$ succuesses in $n$ trials”。可以记作:
$X\sim B(n,p)$
二项分布的计算器计算
menu -> 统计 -> 分布 -> 二项PDF -> 计算 $P(X=k)$
menu -> 统计 -> 分布 -> 二项CDF -> 计算 $P(a \leq X \leq b)$
二项分布的Mean和Standard Deviation
$X \sim B(n,p)$,
期望:
推导:
方差:
推导:
标准差:
Geometric Settings
Definition: A geometric setting arises when we perform independent trials of the same chance process and record the number of trials until a particular outcome occurs. The four conditions for a geometric setting are:
- Binary: The possible outcomes of each trial can be classified as “success” or “failure”
- Independent: Trials must be independent, that is, knowing the result of one trail must not have any effect on the result of any other trial.
- Trials: The goal is to count the number of trials until the first success occurs.
- Success: On each trial, the possibility $p$ must be the same.
要求:
- 结果只有两种,成功或失败
- 每次的事件是独立的
- 目标:统计第一次成功时总共用的次数
- 每次成功概率一样
Geomtric Random Variable
Definition: The number of trials $Y$ that it takes to get a success in a geometric setting is a geometric random variable.
几何分布 - Geometric Distribution
Definition: The probability distribution of $Y$ (which is a geometric random variable) is a geometric distribution with parameter $p$, the probability of success on any trial.
Geometric Probability
$Y \sim G(p)$
几何分布的Mean和Standard Deviation
期望:
标准差:
几何分布的图像
一般是right-skewed的,因为趋向于0。
几何分布的计算器计算
menu -> 统计 -> 分布 -> 几何PDF -> 计算 $P(Y=k)$
menu -> 统计 -> 分布 -> 几何CDF -> 计算 $P(a \leq Y \leq b)$
做题的例子
Let random variable $Y$ denotes …, it satisfies … with ….
连续性随机变量 - Continuous Random Variable
概率密度曲线 - Density Curve
- is always on or above the horizontal axis
- has area exactly 1 underneath it:
对于连续性随机变量,只有区间的概率才有意义,单点的概率趋向于零,且有:
(拓展)概率分布函数:
且概率密度函数是概率分布函数的导数
正态分布 - Normal Distribution
- 自然界中比较正常、自然随机的变量一般都服从正态分布。
- 随机变量$X$服从均值为$\mu$,标准差为$\sigma$的正态分布,记作
正态分布的图像
- Unimodal - 单峰
- Symmetric - 对称
- Bell-shaped - 钟形曲线
经验法则 - The Empirical Rule
- $68\%$ 的数据在 $\mu \pm \sigma$ 范围内
- $95.4\%$ 的数据在 $\mu \pm 2\sigma$ 范围内
- $99.7\%$ 的数据在 $\mu \pm 3\sigma$ 范围内
标准正态分布
- Definition: 标准正态分布就是以$0$为均值$1$为标准差的正态分布。
- 标准正态分布可以说是$z-score$形成的正态分布
- 既然原来的数据是正态分布的,$z-score = \displaystyle\frac {x - \mu}{\sigma}$只是对原来数据进行了线性转换,所以还是服从正态分布的。
- $z-score$的意义是看数据的大小偏离了均值多少个标准差,所以很明显,$z-score$的均值应该是$0$,标准差是$1$(可以通过定义证明,但同样可以通过感性来理解)
标准正态分布表
使用:算出$z-score$查表,就能知道$P(X \leq x_i) = P(z \leq z_i)$
注:标准正态分布表算的概率是小于某个值的概率。
几种不同的情况:
正态分布例题 - Normal Distribution Calculation Example
Women’s heights are $\mathcal N(64, 2.5)$. What percentage of women are shorter than $62$.
$\textit{ Sol. }$ Let a random variable $X$ denotes the womens’s height, $X$ satisfies Normal Distribution. $X \sim \mathcal N(64, 2.5)$. The porportion of women’s heights under $62$ is shown above. (应该在上面画一张图)
Approximately there are $21.19\%$ of women are shorter than $62$.
正态分布的计算器计算
menu -> 统计 -> 分布 -> 正态分布 CDF
- Lower Bound:下界
- Upper Bound:上界
- $\mu$:分布的均值
- $\sigma$:分布的标标准差
- 答案:$P(a < X < b)$
menu -> 统计 -> 分布 -> Inverse Normal
- Area: $P(X < k)$
- $\mu$:分布的均值
- $\sigma$:分布的标准差
- 答案:$k$
正态分布的题目技巧
如果题目中并没有给出均值或者标准差,不妨试试看标准正态分布,求出$z-score$来进行接下来的计算。
抽样分布 - Sampling Distributions
Population VS. Sample
Definition: the value of s statistic varies in repeated random sampling is called sampling variability.
Parameter VS. Statistic
Definition:
- Prarmeter: (unknown) number that describes a characteristic of a population.
- Statistic: (obtained) number that describes a characteristic of a sample drawn from the population.
Parameter描绘总体,Statistic描述样本。
Sampling Distribution
Definition: The Sampling Distribution of a statistic is the distribution of values taken by the statistic in all possible samples of the same size from the same population.
简单的来说,这就是每次抽取的样本的统计量的值所构成的分布。举个例子,现在在对一群人做平均升高的统计,每次抽出300个人,算出平均值,记录下来。如果这样随机抽了10000次,这一千次算出来的平均身高就成为: the sampling distribution of the sample mean.
Sample Distribution, Population Distribution, Sampling Distribution
- Sample Distribution: 指的是在单一一次抽样当中,抽样出的数据形成的分布
- Population Distribution: 指的是总体的分布
- Sampling Distribution: 每一次抽样当中得到的statistic放在一起形成的分布(是统计量形成的分布)
Biased and unbiased estimators
Definition: a statistic used to estimate a parameter is an unbiased estimator if the mean of sampling statistic equals the true value of population parameter.
翻译成人话就是说如果一个统计量是一个不biased,那么
这里的$\bar x$和$\hat p$只是举例,可以换成别的统计量。
Variability of a Statistic
Definition: The variability of a statistic is described by the spread of its sampling distribution. This spread is determined primarily by the size of the random sample. Larger samples give smaller spread. Variability of sampling statistics should be smaller.
翻译成人话:每次抽样数量的多少会影响到Sampling Distribution, 每次抽样得越多,Variability越小,越好。
目标:
- unbiased
- small variability
The Centural Limit Theorem
Draw an SRS of size $n$ from any population with mean $\mu$ and finite standard deviation $\sigma$. The CLT says that when $n$ is large ($n \geq 30$), the sampling distribution of the sample mean $\bar x$ is approximately Normal.
CLT: 在每次抽样的个数变大之后,均值的分布逐渐由不规律转换为正态分布。
Sampling Distribution of a Sample Mean
- Population follow Normal Distribution: $X \sim \mathcal N(\mu, \sigma) \Rightarrow \bar x \sim\mathcal N(\mu, \displaystyle\frac {\sigma}{\sqrt n})$
- Population distribution is skewed / unknown, with $n \geq 30$, $\bar x \sim\mathcal N(\mu, \displaystyle\frac {\sigma}{\sqrt n})$ (According to CLT).
The Sampling Distribution of a Difference Between Two Means
若原分布是正态分布或者$n_1 \geq 30, n_2\geq 30$(根据CLT),那么
证明略(可以通过和上面差不多的方法得到证明)。
Sampling Distribution of $\hat p$
每次抽样,得到抽样的数量的分布可以理解为一个二项分布,这个二项分布除以每次抽样得人数,就形成了一个比例的分布。当满足如下条件时:
有:设$X$表示每次抽样数量的随机变量
推导:
The Sampling Distribution of a Difference Between Two Proportions
If
Then
关于正态分布的一个重要结论
两个独立的正态分布的任意线性组合仍然服从正态分布(现无法证明)
Point Estimator
点估计,需要满足Unbiased and Low Variability:
- Unbiased: 无偏差的,即统计出的值(statistic)和真实的值(parameter)一致
- Low Variability: 更好地情况需要方差更小(可以通过增加sample size)
答题技巧:
- Unbiased和Low Variability都要提到
Confidence Interval / Interval Estimation
因为点估计要满足那些个条件,所以引入了区间估计
$\text {margin of error}$的大小是一个$\text {trade off}$.
Definition: To interpret a $C\%$ confidence interval for an unknown parameter, say, “We are $C\%$ confident that in the long run the interval from $\text {estimate} - \text {margin of error}$ to $\text {estimate} + \text {margin of error}$ would succeed in $\color{red}{capturing}$ the actual value of the [population parameter in context].”
注意:
- 不是probability
- 主语是interval, 谓语是capture
- 估计的是population parameter,而不是sample statistic.
Confidence Level: $1 - \alpha$
举个例子,$95\%$ confidence的interval,$1 - \alpha = 0.95$
临界值 - Critical Value
记作$z^*$或者$z_{\frac \alpha 2}$,可以理解为,在$[-z^*, z^*]$范围内,”区间”可以包含population parameter。 且$P(z < -z^*) = P(z > z^*) = \displaystyle \frac \alpha 2$,$P(-z^* < z < z^*) = 1 - \alpha$。
有了这个临界值之后,我们就可以通过变换来求出每次sample所对应的”区间”:因为$z^*$是处于一个标准正态分布$\mathcal N(\mu = 0,\sigma = 1)$,在临界处与population parameter差了$z^*$个标准差。
以均值这个统计量为例:
术语:
- $\text {standard error} = \text{standard deviation of statistic}$
- $\text {margin of error} = z^* \times \text{standard deviation of statistic}$
所以还可以写成:
对于大多数统计量而言,如果要降低$\text {margin of error}$,有两种方法
- 降低置信区间 $C\% \downarrow$
- 增加每次的抽样数 $n \uparrow$
同样,我们把$z$表达出来也可以写出:
其中$x$为样本的值(statistic),$\mu$为总体均值,$\sigma$为总体标准差,那么
$t$分布 - $t$ Distribution
在我们在根据样本做预测时,我们的统计量会会呈现出一种新的分布,被称为$t$ distribution. 其中
其中,$s_x$为是这个统计量的标准差,其可以转化为关于抽样数据标准差$s$的式子(上面提到过,不同的统计量不同),且有
这里的自由度($\text{degree of freedom}$)是$n-1$,由于找不到很严格的说明方法(只是我太菜了看不懂罢了),有一个形象的理解:
$t$分布的特点
- It is symmetric with a single peak at $0$.
- It has much more data on the tails.
- It has a similar shape like normal distribution, but a greater spread and a lower peak.
用样本的标准差估计的置信区间
因为我们做估计的时候,永远也不可能获得population的标准差,只可能得到sample的标准差,此时就要用自由度为$n-1$的$t$值:
置信区间:$x \pm s_xt^*$
$t$值的计算器查找
menu -> 统计 -> 分布 -> 反向t分布
置信区间的计算器计算
menu -> 统计 -> 置信区间 -> z区间 -> 统计
menu -> 统计 -> 置信区间 -> t区间 -> 统计
menu -> 统计 -> 置信区间 -> 双样本z区间 -> 统计
menu -> 统计 -> 置信区间 -> 双样本t区间 -> 统计
menu -> 统计 -> 置信区间 -> 单比例z区间 -> 统计
menu -> 统计 -> 置信区间 -> 双比例z区间 -> 统计
置信区间的条件
- Random: The data should come from a well-designed random sample or randomized experiment.
- Normal: The sampling distribution is exactly Normal if the population distribution is Normal. In the cases that the population distribution is not normal, the Centural Limit Theorem (CLT) tells us that the sampling distribution of sample mean will be approximately normal if $n$ is large ($n \geq 30$). (For proportions, $np \geq 10, n(1 - p) \geq 10$)
- Independent: Individual observations Individual observations are independent if $n \leq \frac 1 {10} N$. This is called $10\%$ condition.
单样本Mean的置信区间
Population distribution is normal or sample space is large ($n \geq 30$), with $n \leq 10\% N$,
When $\sigma$ is known
When $\sigma$ is unknown
双样本Mean的置信区间
Both population distribution is normal or both sample size is large ($n_1 \geq 30, n_2 \geq 30$), with $n_1 \leq 10\% N_1, n_2 \leq 10\% N_2$,
When $\sigma_1$ and $\sigma_2$ is known
When $\sigma_1$ and $\sigma_2$ is unknown
in which
例题
FRQ One of the two fire stations in a certain town responds to calls in the northern half of the town, and the other fire station responds to calls in the southern half of the town. One of the town council members believes that the two fire stations have different mean response times. Response time is measured by the differnce between the timwe an emergency call comes into the fire station and the time the first fire truck arrives at the scene of the fire. Data were collected to investigate whether the council member’s beliefis correct. A random sample of $50$ calls selected from the northern fire station had a mean response time of $4.3$ minutes with a standard deviation of $3.7$ minutes. A random sample to $50$ calls selected from the southern fire station had a mean response time of $5.3$ minutes with a standard deviation of $3.2$ minutes. Construct and interpret a $95$ percent confidence interval for the difference in mean response times between the two fire stations.
Step 1: State The two-sample $t$ interval for $\mu_N - \mu_S$, the difference in population mean response times, is $(\bar x_N - \bar x_S) \pm t^* \sqrt {\displaystyle\frac{s_N^2}{n_N} + \displaystyle\frac{s_S^2}{n_S}}$, where $\mu_N$ denotes the mean response for calls from the northern fire station and $\mu_s$ denotes the mean response for calls from the southern fire station.
Step 2: Plan Conditions
- Random: A random sample of 50 calls was selected from the northern fire station, and random sample of 50 calls selected from the southern station
- Independent: The calls of the northern are independent from the calls of the southern.
- Normal (稍微详细写一点): The use of the two-sample $t$ interval is reasonable beacause both sample sizes are large ($n_N = 50 > 30$ and $n_S = 50 > 30$), and by Centural Limit Theorem, the sampling distributions for the two sample means are approximately normal. Therefore the sampling distribution of the difference of the sample means $\bar x_N - \bar x_S$ is approximately normal.
Step 3: Do
$\text{The Degree of freedom}= 96$
Step 4: Interpretation Based on these samples, one can be $95$ percent confident that the difference in the population mean response times (northern - southern) is between $-2.37$ minutes and $0.37$ minutes.
The One-Sample for Matched-Pairs Sample
对于这样的单样本数据,(如果我们要看pair里面的差的分布,使用$d = x_1 - x_2$,并且看的是$\bar d$的分布而非$\bar x_1 - \bar x_2$
单样本Prop的置信区间
Using the normal approximation as long as $n\hat p \geq 10, n(1 - \hat p) \geq 10$, and independent, $n \leq 10\% N$,
用$\hat p$估计替代$p$,而且在Prop里只有$z$分布:
双样本Prop的置信区间
Using the normal approximation as long as $n_1\hat p_1 \geq 10, n_1(1 - \hat p_1) \geq 10, n_2\hat p_2 \geq 10, n_2(1 - \hat p_2) \geq 10$, and independent, $n_1 \leq 10\% N_1, n_2 \leq 10\% N_2$,
用$\hat p_1$估计替代$p_1$,$\hat p_2$估计替代$p_2$,而且在Prop里只有$z$分布:
Hypothesis Test
Introduction
Hypothesis test statistical idea: flasifiability 可证伪性
显著性实验 - Significance Test
Definition: A significance test is a formal procedure for comparing observed data with a claim whose truth we want to assess. This claim is a statement about a parameter, like the population proportion $p$ or the population mean $\mu$. We express the results of a significance test in terms of a probability that measures how well the data and the claim agree.
Null Hypothesis & Alternative Hypothesis
要推翻的理论:Null Hypothesis ($H_0$)
支持的理论:Alternative Hypothesis ($H_a$)
Test Statistic
Definition: A test statistic measures how far a sample statistic diverges from what we would expect if the null hypothesis $H_0$ were true, in standardized units. That is
显著程度 - Significance Level $\alpha$
The significance level ($\alpha$) defined for a study is the probability of the study rejecting the null hypothesis, given that it were true.
Stating Hypothesis (left-tailed test)
When
If
then $H_0$ can be rejected.
Stating Hypothesis (right-tailed test)
When
If
then $H_0$ can be rejected.
Stating Hypothesis (two-tailed test)
When
If
then $H_0$ can be rejected.
标准差$\sigma$未知的情况
和CI问题相同,使用$t$分布来替代$z$分布,使用$s$代替$\sigma$,上述过程中的所有Inverse-z替换成Inverse-t.
$P-\text {Values}$
$t$值和$z$值不方便,不直接,不直观,所以引入了$P-\text {Values}$.
Definition: P-value is the probability that we observe a test statistic value at least as extreme as the one computed from the sample, if $H_0$ were true.
计算方法:计算$t$分布或$z$分布的CDF
- left-tailed: $P(z < \text {test statistic})$或者$P(t < \text {test statistic})$
- right-tailed: $P(z > \text {test statistic})$或者$P(t > \text {test statistic})$
- two-tailed: $P(|z| > |\text {test statistic}|)$或者$P(|t| > |\text {test statistic}|)$
$P-\text {Values}$得到的结论
Type I and Type II Errors
拒真错误 - Type I Error
Definition: 当$H_0$为真,reject $H_0$.
受伪错误 - Type II Error
Definition: 当$H_0$为假,fail to reject $H_0$.
Power - $1 - \beta$
Definition: 当$H_0$为假,成功reject的概率就是Power,为$1 - \beta$.
增加Power的方法:
- 增加$\alpha$
- 增加Sample Size
HT问题的Conditions
和CI问题的Conditions差不多,还是三个条件:
- Random: The data should come from a well-designed random sample or randomized experiment.
- Independent: Individual obervations are independent if $n \leq \displaystyle\frac{1}{10}N$
- Normal:
- Normal if the original distribution is Normal.
- Normal according to Central Limit Theorem when $n \geq 30$.
- Normal when approximating by Binomial Distribution and $np \geq 10$, $n(1 - p) \geq 10$.
- 在题目中没有提及且是小样本的情况下:
- 画Dot Plot
- Since the graph reveal no obvious skewness or outliers, we assume that the distribution is approximately normal.
The One-Sample $z$ Test
When conditions are met, we can test a claim about a poulation mean $\mu$ using a one-sample $z$ test.
one-sample $z$ statistic:
The One-Sample $t$ Test
When conditions are met, we can test a claim about a population mean $\mu$ using a one-sample $t$ test.
one-sample $t$ statistic:
Two-Sample $z$ Test for The Difference Between Two Means
Suppose the Random, Normal and Independent conditions are met. To test the hypothesis $H_0: \mu_1 - \mu_2 = \text {hypothesis value}$, compute the $z$ statistic
Two-Sample $t$ Test for The Difference Between Two Means
Suppose the Random, Normal and Independent conditions are met. To test the hypothesis $H_0: \mu_1 - \mu_2 = \text {hypothesis value}$, compute the $t$ statistic
Paired-Data $t$ / $z$ Test
The One-Sample $z$ Test for a Proportion
Choose an SRS of size $n$ from a large population that contains an unknown proportion $p$ of successe. To test the hypothesis $H_0 : p = p_0$, compute the $z$ statistic
Two-Sample $z$ Test for the Difference Between Two Proportions
Suppose the Random, Normal, and Independent conditions are met. To test the hypothesis $H_0 : p_1 - p_2 = 0$, first find the pooled proportion $\hat p_C$ of successes in both samples combined
Then compute the $z$ statistic
例题
FRQ Investigators at the U.S. Department of Agriculture wished to compare methods of determining the level
of $E$ coli bacteria contamination in beef. Two different methods (A and B) of determining the level of contamination were used on each of ten randomly selected specimens of a certain type of beef. The data obtained, in millimicrobes/liter of ground beef, for each of the methods are shown in the table below.
Is there a significant difference in the mean amount of $E$. coli bacteria detected by the two methods for this type of beef? Provide a statistical justification to support your answer.
Step 1: State
where $\mu_d$ is the mean difference (method A - method B) in the level of E. coli bacteria contamination in beef detected by the two methods.
Thus, we are gonna use the Paired $t$-test, where
Step 2: Plan
Conditions:
- Since the observations are obtained on 10 randomly selected specimens, it is reasonable to assume that the 10 data pairs are independent of one another.
- The population distribution of differences is normal. (画图,说为什么Normal)
The computed differences are:
Step 3: Do
Step 4: Intepretation
Since the $P$ -value is greater than $0.05,$ we cannot reject $H_{0} .$ We do NOT have statistically significant evidence to conclude that there is a difference in the mean amount of $E$. coli bacteria detected by the two methods for this type of beef. In other words, there does not appear to be a significant difference in these two methods for measuring the level of $E$. coli contamination in beef.
HT 2012 FRQ


HT的计算器计算
menu -> 统计 -> 统计检验 -> z检验
menu -> 统计 -> 统计检验 -> t检验
menu -> 统计 -> 统计检验 -> 双样本z检验
menu -> 统计 -> 统计检验 -> 双样本t检验
menu -> 统计 -> 统计检验 -> 单比例z检验
menu -> 统计 -> 统计检验 -> 单比例t检验
Inference for Categorical Data: Chi-Square
卡方统计量 - The Chi-Square Statistic
Definition: The Chi-Square Statistic is a measure of how far the observed counts are from the expected counts. The formula for the statistic is
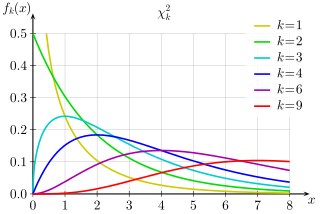
The Chi-Square Distributions and P-Values
The chi-square distributions are a family of distributions that take only positive values and are skewed to the right.
A particular chi-square distribution is specified by giving its degrees of freedom.
The Chi-Square Goodness-of-Fit Test
Null Hypothesis & Alternative Hypothesis
Conditions
- Random: The data come from a random sample or a randomized experiment
- Independent: Individual observations are independent if $n \leq \displaystyle\frac {1}{10}N$. This is called $10\%$ condition.
- Large Sample Size: All expected counts are at least $5$.
The Chi-Square GOF Test
Suppose the conditions are met. Start by finding the expected count for each category assuming that $H_0$ is true. Then calculate the chi-square statistic. The P-value is the area to the right of chi-square distribution with $k - 1$ degrees of freedom.
The Chi-Square Test for Association / Independence
Null Hypothesis & Alternative Hypothesis
Conditions
- Random: The data come from a random sample or a randomized experiment
- Large Sample Size: All expected counts are at least $5$.
Calculations
in which the expected value is given by
The degree of freedom is
Inference for Quantitative Data: Slope
Least Regression Line的斜率$b$也是一个统计量,所以也可以做CI和HT问题。这里直接给出众多公式:
Least Regression Line
Line Predicted from the sample:
Line for the population:
Sampling Distribution of a Slope
- The Mean of the sampling distribution of $b$ is $\mu_b = \beta$
- The Standard Deviation of the sampling distribution of $b$ is
- The Standard Error of $b$ is $s$是$b$的标准差,$s_x$是原始数据中$x$的标准差。
Confidence Interval
Hypothesis Test
Test Statistic
计算器使用汇总
- 定义变量:define xxx = xxx
- 矩阵:menu -> 矩阵与向量 -> 创建 -> 矩阵
- 求统计量:menu -> 统计 -> 数组计算 -> 需要的统计量 -> 填入数组名称 这里数组的计算都是根据列来的,如果有$n$个数据,创建$n$行$1$列的矩阵进行运算。
- 组合:menu -> 概率 -> 组合,e.g. nCr(5, 3) = 10.
- 二项分布PDF:menu -> 统计 -> 分布 -> 二项PDF -> 计算 $P(X=k)$
- 二项分布CDF:menu -> 统计 -> 分布 -> 二项CDF -> 计算 $P(a \leq X \leq b)$
- 几何分布PDF:menu -> 统计 -> 分布 -> 几何PDF -> 计算 $P(Y=k)$
- 几何分布CDF:menu -> 统计 -> 分布 -> 几何CDF -> 计算 $P(a \leq Y \leq b)$
- 正态分布的概率:menu -> 统计 -> 分布 -> 正态分布 CDF
- Lower Bound:下界
- Upper Bound:上界
- $\mu$:分布的均值
- $\sigma$:分布的标标准差
- 答案:$P(a < X < b)$
- 反向正太分布:menu -> 统计 -> 分布 -> Inverse Normal
- Area: $P(X < k)$
- $\mu$:分布的均值
- $\sigma$:分布的标准差
- 答案:$k$
- 反向$t$分布:menu -> 统计 -> 分布 -> 反向t分布 Area就是从左到右的面积,在计算时取$\displaystyle\frac{\alpha}{2}$。也就是说如果要$90\%$的置信区间,取$0.025$df ($\text{degree of freedom}$): 自由度
- menu -> 统计 -> 置信区间 -> z区间 -> 统计
- menu -> 统计 -> 置信区间 -> t区间 -> 统计
- menu -> 统计 -> 置信区间 -> 双样本z区间 -> 统计
- menu -> 统计 -> 置信区间 -> 双样本t区间 -> 统计
- menu -> 统计 -> 置信区间 -> 单比例z区间 -> 统计
- menu -> 统计 -> 置信区间 -> 双比例z区间 -> 统计
- menu -> 统计 -> 统计检验 -> z检验
- menu -> 统计 -> 统计检验 -> t检验
- menu -> 统计 -> 统计检验 -> 双样本z检验
- menu -> 统计 -> 统计检验 -> 双样本t检验
- menu -> 统计 -> 统计检验 -> 单比例z检验
- menu -> 统计 -> 统计检验 -> 单比例t检验 在比例部分,$x$是成功次数:$x = \hat pn$,其中$\hat p$是实验抽样的概率,$n$是Sample Size。
- menu -> Statistic -> Stat Tests -> $\chi^2$ GOF Observed List: 一个数组,在TI-nspire中可以表示为$\{n1, n2, n3, ...\}$Expected List: 一个数组,同上Degree of Freedom: 自由度,$k - 1$
- menu -> Statistics -> Stat Tests -> $\chi^2$ 2-way Test Matrix: 创建矩阵(menu -> Matrix & Vector -> Create -> Matrix)
尾声
八个夜晚,一人,一电脑,一笔,一个奇迹。
AP 2020 特辑
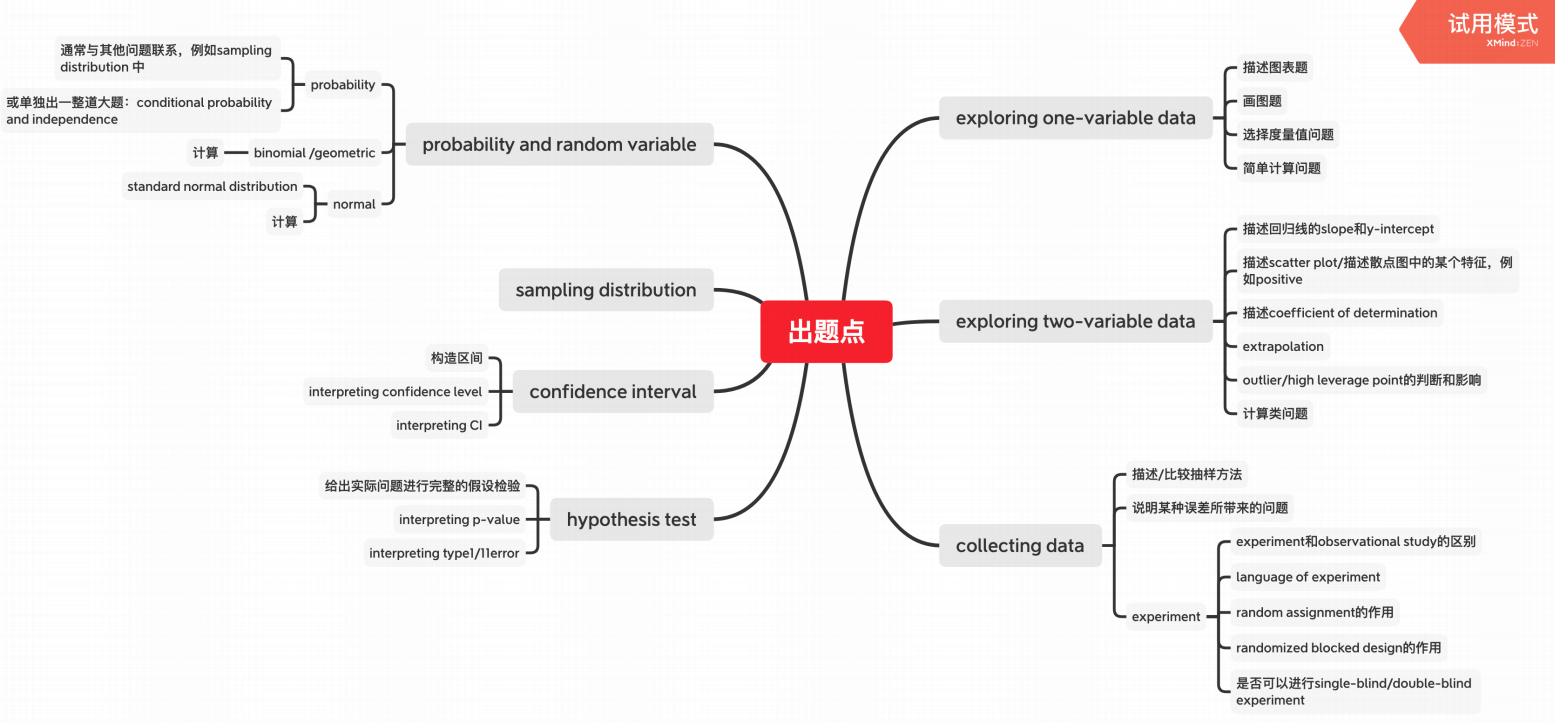
出题点
答题切记
Unit 1 - 单变量
描述图表题
- Shape
- Symmetric Distribution
- 对称的分布
- Median = Mean
- Left-Skewed Distribution
- 左偏分布
- 数据集中在右边
- Mean < Median
- Right-Skewed Distribution
- 右偏分布
- 数据集中在左边
- Mean > Median
- Uniform Distribution
- 非常平均的
- 就像一条水平线一样的
- Bimodal Distribution
- 双峰分布
- Symmetric Distribution
- Outliers
- 有 / 无 / 位置?
- Center
- Median / Mean
- Spread
- IQR / Range
画图题
比如画箱型图 Box-Plot
- 一定要判断Outlier
- 上界:Q3 + 1.5IQR
- 下界:Q1 - 1.5IQR
- 新方法:$\text {Mean} \pm 2 \text { Std Dev}$
选择度量问题
- 为什么Median不Mean
- 因为Median是Resistent to outliers
- 为什么IQR不Standard Deviation
- 因为IQR是Resistent to outliers
简单计算问题
- IQR = Q3 - Q1
Unit 2 - 双变量
描述回归线的Slope和y-Intercept
结合实际问题:
- Slope: the amount by which y is predicted to change when x increases by 1 unit.
- y-Intercept: predicted value of y when x = 0.
读表格

图中,Slope = 174.40, y-Intercept = 72.95, $R^2$ = 73.33%
描述Scatter Plot
- Direction
- Positive / Negative
- Positive: xxxx Increase as xxxx Increase
- Negative: xxxx Decrease as xxxx Increase
- Form
- Linear / Nonlinear / Curve / …
- Linear: When xxxx is increased by 1 unit, xxxx will also increase by a constant unit by average.
- Strength
- Strong / Moderate / Weak / …
- Strong: Points are close to a line.
- Weak: Points are far away to a line.
- Outlier
- 有 / 无 / 位置?
描述$R^2$ (Coefficient of Determination)
About $R^2$ of the varaibility of xxxxxx can be accounted for by the linear relationship between xxxxxx and xxxxxx.
描述$r$ (Correlation)
- Definition $r$ is a measure of the direction and strength of the linear relationship between two quantitative variables.
- $-1≤r≤1$
- $r > 0$: Positive Association
- $r < 0$: Negative Association
- 越Strong,绝对值越大
- 但是绝对值越大,不一定越Strong,因为不一定成线性关系
Extrapolation - 越界
Explain不能推广(就是越界)的答题格式:
No, This is extrapolation beyond the …. data. xxxxxxx data were not investigated.
Outlier / High Leverage Point的判断和影响
双变量的计算问题
Unit 3 - Collecting Data
描述抽样方法
- SRS - Simple Random Sample: Label the subjects (students, patients, etc.) from 1 to N (N = population size). Use random number generator in the calculator randInt(1, N) to generate n (n = sample size) different numbers and select these n corresponding subjects (students, patients, etc.) for the sample.
- Stratified Random Sample: In each strata (gender, plots, etc.), label the individuals (students, trees, etc.) in this strata from 1 to n (n is the number of individuals in this strata). Use randInt(1, n) to generate m different numbers and select these m different numbers for the sample. Repeat this procedure for every strata (genders, plots, etc.).
- 注:每个Stata内部的差异越小越好,不同Stata之间的差异越大越好,最终在每个Stata的内部抽样
- Cluster Random Sample: Label all the clusters (plots, gender, etc.) from 1 to n (n = total number of clusters). Use random number generator in the calculator randInt(1, n) to generate m different numbers. Select all the individuals in these m corresponding clusters for the sample.
- 注:每个Cluster内部差异越大越好,不同Cluster之间的差异越小越好,最终抽取几个Cluster
比较抽样方法
- Cluster的优点:省事. Easier to obtain.
- Stratified的有点:Low Variability. result in a better representative of the population.
说明某种误差带来的问题
- Selection Bias
- Under Coverage: 覆盖不全
- Non-selection Bias:
- Non-response Bias: 样本没有回复,比如说人联系不上或者拒绝回答
- Response Bias: 骗人
- Wording of Questions: 用词不当造成的误差
Experiment和Observational Study的区别
- Experiment: 人为施加措施,attempt to impose treatment
- Observational Study: 只是看
Language of Experiment
- Treatment: 干的事情
- Experimental Units: The smallest collection of individuals to which treatments are applied. 比如说,在不同瓶子里喷洒农药看虫子的存活情况中,Experimental Units是这些瓶子。
- Response Variable: 反馈的变量
如何Random Assignment
- 标号
- 计算器随机生成
- 根据生成的数来assign
Random Assignment 的好处
防止 Confounding Variables 影响实验结果
Control Group
A Group that is not assigned of any treatment.
Control Group 的好处
A control group gives the researchers a comparison group to be used to evaluate the effectiveness of the treatments (medication, therapy, etc.), in comparison with normal effect (context) of control group on the response variable (context).
Randomized Blocked Design
把对象根据不同的feature进行分组,然后在组内进行random的抽取
Randomized Blocked Design 的好处
lower 组内的 Variability
是否可以Single-Blind / Double-Blind
单盲(single blind)
- 只有研究者了解分组情况,研究对象不知道自己是试验组还是对照组。
- 这种盲法的优点是研究者可以更好地观察了解研究对象,在必须时可以及时恰当地处理研究对象可能发生的意外问题,使研究对象的安全得到保障。
- 缺点是避免不了研究者方面带来的主观偏倚,易造成试验组和对照组的处理不均衡。
双盲(Double Blind)
双盲试验,是指在试验过程中,测验者与被测验者都不知道被测者所属的组别(实验组或对照组),分析者在分析资料时,通常也不知道正在分析的资料属于哪一组。旨在消除可能出现在实验者和参与者意识当中的主观偏差和个人偏好。在大多数情况下,双盲实验要求达到非常高的科学严格程度。

