原论文:
Very Deep Convolutional Networks for Large-Scale Image Recognition
- arXiv:[1409.1556] Very Deep Convolutional Networks for Large-Scale Image Recognition
- intro:ICLR 2015
- homepage:Visual Geometry Group Home Page
下图为VGG网络的网络结构
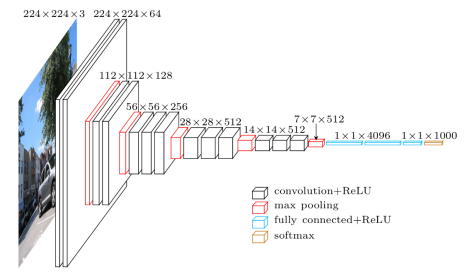
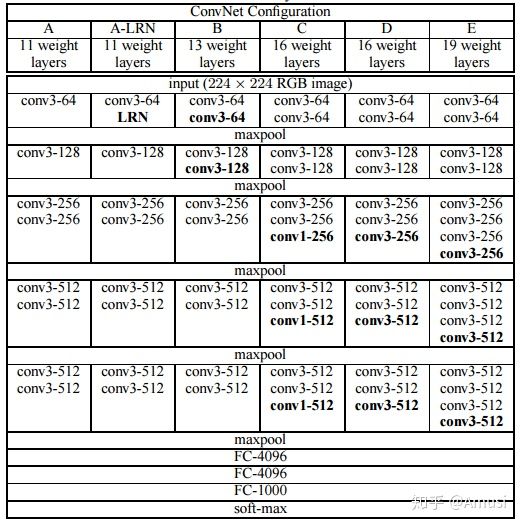
在这里我就不多赘述为什么要用小卷积核,小卷积核有什么好处,感受野,等等,诸如此类问题。这些东西网上讲解的非常详尽。我这里主要想探讨一下关于VGG可以接受任意大小的图片的原因。
众所周知,卷积层和池化层不会对长宽有着硬性规定。因为卷积层迭代的其实就是卷积核当中的参数,与输入做卷积运算,不会有什么影响。注意到最后的全连接层。全连接层其实是可以和卷积层互换的,而且他们的参数规模都是一样的。具体原因,可以看下面这篇文章:
https://blog.csdn.net/jyy555555/article/details/80515562
引用:
上图是VGG网络最后三层的替换过程,上半部分是训练阶段,此时最后三层都是全连接层(输出分别是4096、4096、1000),下半部分是测试阶段(输出分别是1x1x4096、1x1x4096、1x1x1000),最后三层都是卷积层。下面我们来看一下详细的转换过程(以下过程都没有考虑bias,略了):
先看训练阶段,有4096个输出的全连接层FC6的输入是一个7x7x512的feature map,因为全连接层的缘故,不需要考虑局部性, 可以把7x7x512看成一个整体,25508(=7x7x512)个输入的每个元素都会与输出的每个元素(或者说是神经元)产生连接,所以每个输入都会有4096个系数对应4096个输出,所以网络的参数(也就是两层之间连线的个数,也就是每个输入元素的系数个数)规模就是7x7x512x4096。对于FC7,输入是4096个,输出是4096个,因为每个输入都会和输出相连,即每个输出都有4096条连线(系数),那么4096个输入总共有4096x4096条连线(系数),最后一个FC8计算方式一样,略。
再看测试阶段,由于换成了卷积,第一个卷积后要得到4096(或者说是1x1x4096)的输出,那么就要对输入的7x7x512的feature map的宽高(即width、height维度)进行降维,同时对深度(即Channel/depth维度)进行升维。要把7x7降维到1x1,那么干脆直接一点,就用7x7的卷积核就行,另外深度层级的升维,因为7x7的卷积把宽高降到1x1,那么刚好就升高到4096就好了,最后得到了1x1x4096的feature map。这其中卷积的参数量上,把7x7x512看做一组卷积参数,因为该层的输出是4096,那么相当于要有4096组这样7x7x512的卷积参数,那么总共的卷积参数量就是:
[7x7x512]x4096,这里将7x7x512用中括号括起来,目的是把这看成是一组,就不会懵。
第二个卷积依旧得到1x1x4096的输出,因为输入也是1x1x4096,三个维度(宽、高、深)都没变化,可以很快计算出这层的卷积的卷积核大小也是1x1,而且,通道数也是4096,因为对于输入来说,1x1x4096是一组卷积参数,即一个完整的filter,那么考虑所有4096个输出的情况下,卷积参数的规模就是[1x1x4096]x4096。第三个卷积的计算一样,略。
其实VGG的作者把训练阶段的全连接替换为卷积是参考了OverFeat的工作,如下图是OverFeat将全连接换成卷积后,带来可以处理任意分辨率(在整张图)上计算卷积,而无需对原图resize的优势。
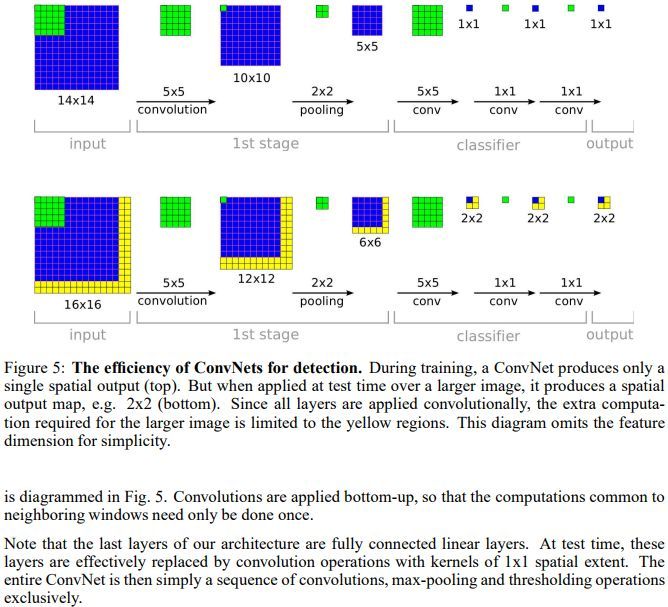
Digression:前段时间看了RCF网络,他之所以可以输出和输入同样尺寸的图片,就是因为其只有卷积层和池化层,去除了所有全连接层。

